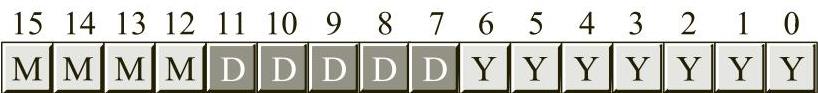第1章 汇编语言的第一个程序
本章是一个“快速入门”章节,可以让读者尽快开始编写基本的汇编语言程序。通过本章的学习,读者应该了解MASM的基本语法,以及后续章节中学习汇编语言新功能所需的先决条件。
注意: 本书使用在Windows环境下运行的MASM,因为它是迄今为止编写x86-64汇编语言程序最常用的汇编器。此外,英特尔文档通常使用与MASM语法兼容的汇编语言示例。读者在现实世界中遇到的x86源代码,就很有可能是使用MASM编写的。也就是说,还有许多其他流行的x86-64汇编器,包括GNU汇编器(gas)、Netwide汇编器(NASM)、Flat汇编器(FASM)等。这些汇编器所使用的语法与MASM不同(gas的语法与其区别最大)。在某种程度上,如果读者经常使用汇编语言,就可能会遇到使用其他汇编器编写的源代码。不要因此感到焦躁不安,因为一旦掌握了使用MASM的x86-64汇编语言,学习各种汇编器之间的语法差异就没那么困难了。
本章将涵盖以下内容:
●MASM程序的基本语法
●英特尔中央处理器(central processing unit,CPU)的体系结构
●如何为变量保留内存
●使用机器指令控制CPU
●将MASM程序与C/C++代码相链接,以便可以调用C标准库中的例程
●编写一些简单的汇编语言程序
1.1 先决条件
学习使用MASM进行汇编语言程序设计需要如下的先决条件:一个64位版本的MASM和一个文本编辑器(用于创建和修改MASM源文件)、链接器、各种库文件,以及C++编译器。
如今,只有当C++、C#、Java、Swift或Python代码运行速度太慢,而且需要提高代码中某些模块(或函数)的性能时,软件工程师才会采用汇编语言。在现实世界中使用汇编语言时,通常会编写C++或其他高级语言(HLL)代码来调用汇编语言。在本书中,我们也将采用相同的模式。
使用C++的另一个原因是C标准库。虽然不同的个体为MASM创建了若干实用的库(典型的例子请参见http://www.masm32.com/),但没有一套公认的标准库。为了使MASM程序能够方便地访问C标准库,本书提供了一个简短的C/C++主函数示例,该函数调用使用MASM汇编语言编写的单个外部函数。编译C++主程序和MASM源文件将生成一个可运行的文件,用户可以运行和测试该文件。
学习汇编语言需要掌握C++吗?答案是并非必需。本书将为读者提供运行示例程序所需的C++代码。尽管如此,汇编语言并不是入门程序设计语言的最佳选择,因此本书假设读者对其他计算机程序设计语言,例如C/C++、Pascal(或Delphi)、Java、Swift、Rust、BASIC、Python或任何其他命令式及面向对象的程序设计语言有一定的了解。
1.2 在计算机上安装 MASM
MASM是微软公司的产品,它是Visual Studio开发工具套件的一部分。因为MASM是微软的工具集,所以读者需要运行某个版本的Windows(在编写本书时,Windows 10是最新版本,不过Windows 10以后的任何新版本也都可能满足要求)。附录A提供了如何安装Visual Studio社区版的完整说明。Visual Studio社区“免费”版包括MASM和Visual C++编译器,以及其他使用者需要的工具。有关更多详细信息,请参阅附录A。
1.3 在计算机上安装文本编辑器
Visual Studio包含一个文本编辑器,可以用来创建和编辑MASM与C++程序。为了获取MASM,用户必须安装Visual Studio包,因此会自动获得一个产品质量级别的程序员文本编辑器,可以用于编辑汇编语言源文件。
当然,用户也能使用任何可以直接处理ASCII文件(或UTF-8)的编辑器,例如https://www.masm32.com/上提供的文本编辑器,来创建MASM和C++源文件。文字处理程序(例如Microsoft Word)不适用于编辑程序源文件。
1.4 MASM 程序的结构剖析
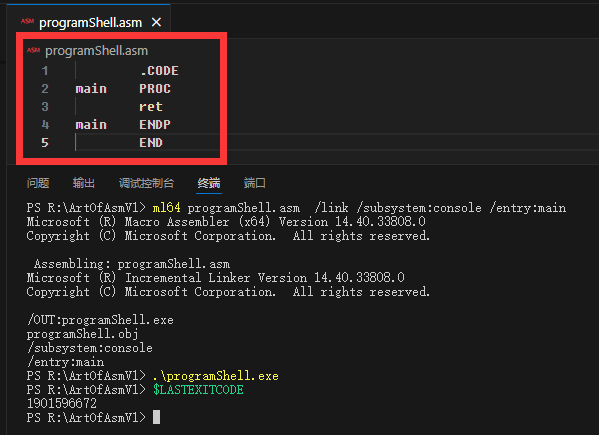
一个典型的(并且可以独立运行的)MASM程序如程序清单1-1所示。
程序清单 1-1 一个简单的 shell 程序( programShell.asm 文件)
;注释是从一个分号字符开始到行尾的所有文本。
;“.code”伪指令指示MASM该指令后的语句位于保留给机器指令(代码)的内存段(section)中。
.code
;以下是“main”主函数的定义。
;(本示例假定该汇编语言程序是一个独立可运行的程序,拥有自己的main主函数。)
main PROC
;此处包含机器指令
ret;返回到调用方
main ENDP
;END伪指令标记源代码文件的结束。
END
典型的MASM程序包含一个或多个段,段表示内存中出现数据的类型。这些段以MASM语句(例如“.code”或“.data”)开始。变量和其他内存值均位于数据段(data section)中,汇编语言过程中的机器指令位于代码段(code section)中。在汇编语言源文件中,不同的段是可选的,因此特定的源文件中并非包含每种类型的段。例如,程序清单1-1只包含一个代码段。
在程序清单1-1中,“.code”语句是一条汇编伪指令。汇编伪指令的功能是指示MASM有关程序的一些信息,并不是实际的x86-64机器指令。具体而言,“.code”伪指令指示MASM将其后面的语句分组到一个特殊的内存段中,而这个内存段是专门为机器指令预留的。
1.5 运行第一个 MASM 程序
按程序设计语言界的惯例,用新学语言写的第一个程序是“Hello,world!”程序,该程序出自Brian Kernighan和Dennis Ritchie编写的 The C Programming Language (Prentice Hall出版社,1978年),随后开始流行。“Hello,world!”程序的主要目标是提供一个简单的示例,让学习一种新程序设计语言的人可以使用该示例了解如何使用该语言提供的工具去编译和运行程序。
遗憾的是,在汇编语言中,编写类似于“Hello,world!”这样简单的程序却需要先学习大量的汇编知识。为了打印字符串“Hello,world!”,必须学习一些机器指令和汇编伪指令,还需要学习Windows的系统调用方法。就这一点而言,可能给刚开始使用汇编语言的程序员提出了过高的要求。当然,对于那些迫不及待想挑战并自行完成这个编程任务的人,可以参见附录A中的示例程序。
程序清单1-1中的程序shell实际上是一个完整的汇编语言程序。用户可以编译(汇编)并运行该程序,程序不产生任何输出。启动后,程序会立即返回Windows。但是,该程序确实可以运行,它将作为一种机制,向用户展示如何汇编、链接和运行一个汇编语言源文件。
MASM是一个传统的命令行汇编器,这意味着用户需要从Windows命令行提示符窗口运行MASM(用户可以通过运行cmd.exe程序打开Windows命令行)。为了执行此操作,请在Windows命令行提示符窗口或者shell窗口中输入以下内容:
C:\> ml64 programShell.asm/link/subsystem:console/entry:main
以上命令指示MASM对programShell.asm程序(注意,程序清单1-1被保存为programShell.asm文件)进行汇编,生成一个可执行文件,并将结果进行链接以生成一个控制台应用程序(用户可以从命令行运行这个应用程序),然后在汇编语言源文件的标签main处开始执行。假设汇编和链接的过程中没有发生错误,则可以通过在命令行提示符窗口中键入以下命令来运行所生成的结果程序:
C:\> programShell
Windows立即响应一个新的命令行提示符(因为programShell应用程序在开始运行之后立即将控制权返回给Windows)。
1.6 运行第一个 MASM 和 C++ 的混合程序
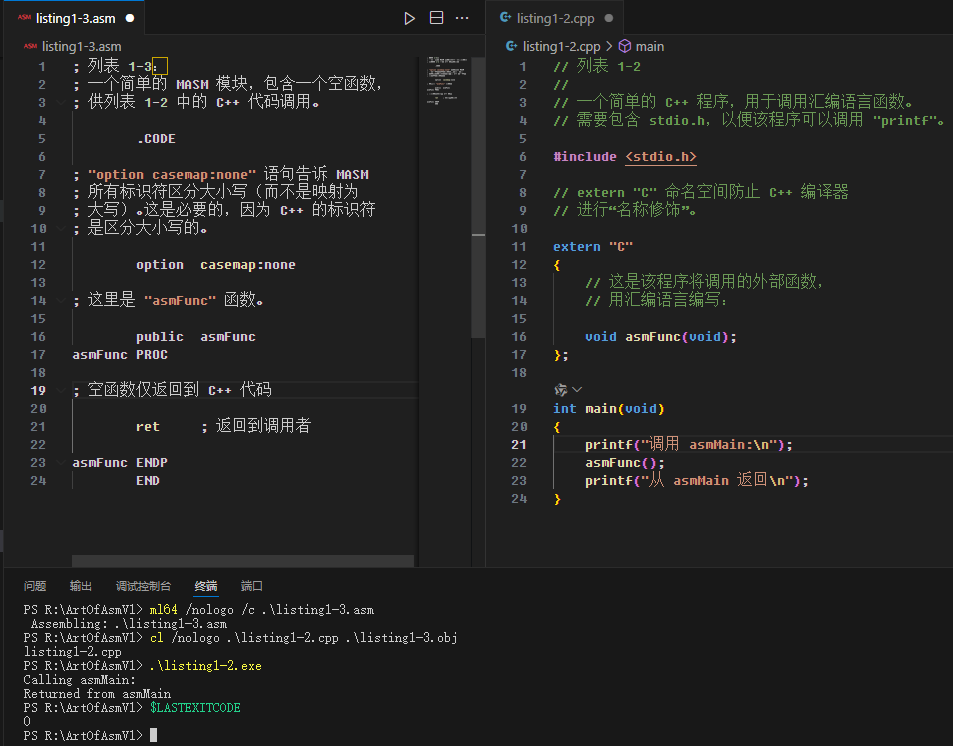
本书通常将汇编语言模块(包含一个或多个使用汇编语言编写的函数)与调用它的C/C++主程序相结合。由于由汇编语言和C++语言组成的混合程序的编译及执行过程与独立MASM程序的略有不同,因此本节将演示如何创建、编译和运行这样一个混合程序。程序清单1-2提供了调用汇编语言模块的C++主程序。
程序清单 1-2 示例 C/C++ 程序( listing1-2.cpp 文件),该程序调用了汇编语言函数
//程序清单1-2
//一个简单的C++程序,该程序调用了一个使用汇编语言编写的函数。
//需要包含stdio.h头文件,以便程序能够调用“printf”函数。
#include<stdio.h>
//extern“C”命名空间可以防止C++编译器的“名称篡改”。
extern"C"
{
//以下是使用汇编语言编写的外部函数,本程序将调用该函数:
void asmFunc(void);
};
int main(void)
{
printf("Calling asmMain:\n");
asmFunc();
printf("Returned from asmMain\n");
}
程序清单1-3是可独立运行MASM程序的改进版,其中包含asmFunc()函数,此函数被C++程序调用。
程序清单 1-3 MASM 程序( listing1-3.asm 文件),被程序清单 1-2 中的 C++ 程序调用
;程序清单1-3
;一个简单的MASM模块,包含一个空函数,被程序清单1-2中的C++代码调用。
.CODE
;(有关option伪指令的说明,请参见后续正文。)
option casemap:none
;以下是“asmFunc”函数的定义。
public asmFunc
asmFunc PROC
;空函数,直接返回到C++代码。
ret;返回到调用方
asmFunc ENDP
END
相对于原始的programShell.asm源文件,程序清单1-3包括三处修改。首先,有两个新的语句,即option语句和public语句。
option语句指示MASM将区分所有符号的大小写。这是非常必要的操作,因为在默认情况下,MASM不区分大小写,并将所有标识符映射为大写(意味着asmFunc()函数将转换为ASMFUNC())。而C++是区分大小写的程序设计语言,会将asmFunc()和ASMFUNC()视为两种不同的标识符。因此,必须指示MASM区分标识符的大小写,以免混淆C++程序的语义。
注意: MASM标识符可以以美元符号($)、下划线(_)或字母字符开头,后面跟零个或多个字母、数字字符、美元符号或下划线字符。标识符本身不能由$字符组成($符号在MASM中具有特殊意义)。
public语句声明asmFunc()标识符将对MASM源文件和目标文件的外部可见。如果没有该语句,那么只能在MASM模块内访问asmFunc(),C++编译就会报错:asmFunc()是一个未定义的标识符。
程序清单1-3和程序清单1-1之间的第三个区别是,函数名从main()更改为asmFunc()。如果在汇编代码中使用名称main(),则由于C++程序中也包含一个名称为main()的函数,因此C++编译器和链接器会出现混乱。
为了编译和运行这些源文件,可以使用如下所示的命令:
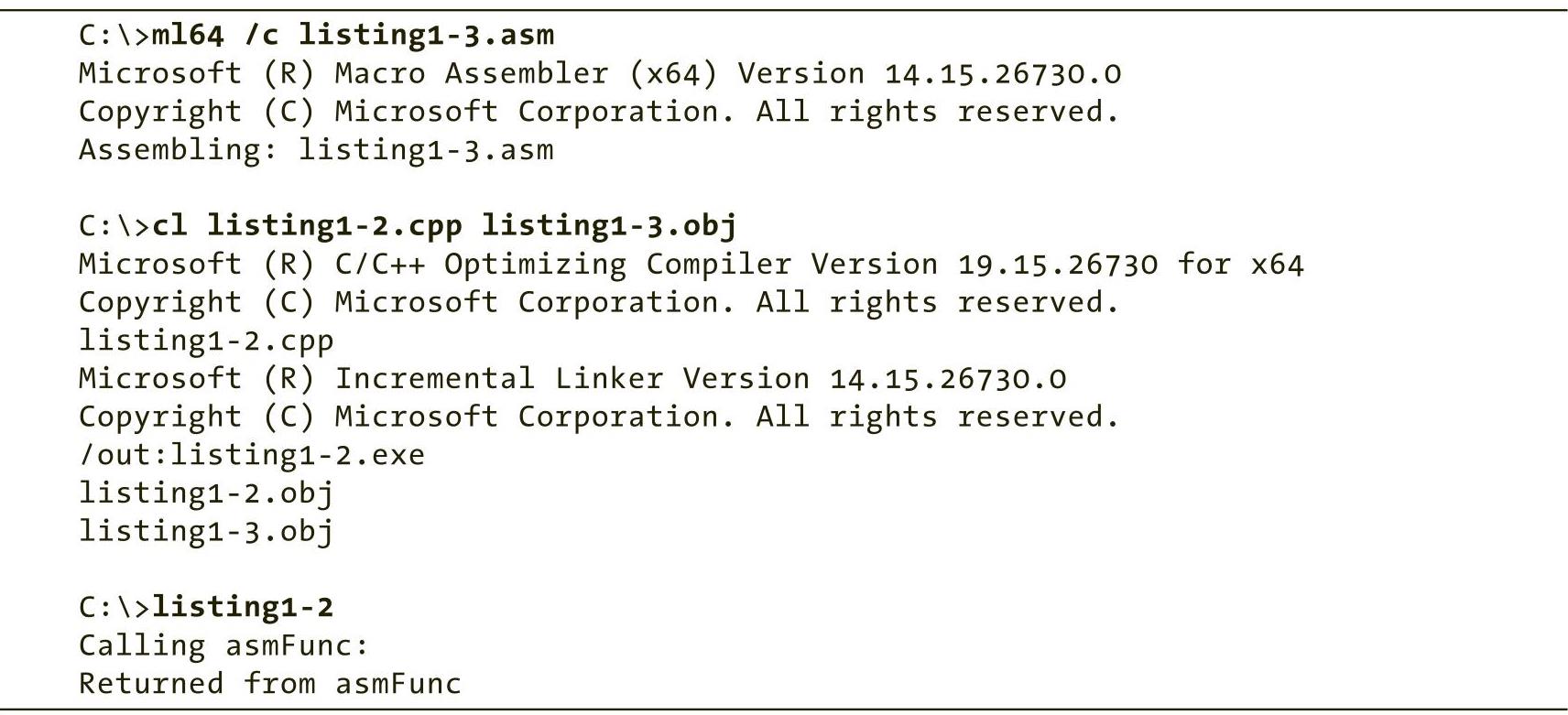
ml64命令使用了“/c”选项,该选项表示“仅编译”,并且不尝试运行链接器(如果运行链接器则将失败,因为listing1-3.asm不是一个可独立运行的程序)。MASM的输出是一个目标代码文件(listing1-3.obj),该文件作为下一个命令中Microsoft Visual C++(MSVC)编译器的输入。
cl命令在listing1-2.cpp文件上运行MSVC编译器,并将汇编代码(listing1-3.obj)进行链接。MSVC编译器的输出是一个可执行文件listing1-2.exe,从命令行执行该程序就会产生预期的输出结果。
1.7 英特尔 x86-64 CPU 系列简介
到目前为止,读者已经学习了一个可以编译并运行的MASM程序。然而,该程序没有执行任何操作,只是将控制权返回到Windows。在进一步学习真正的汇编语言之前,必须先了解硬件方面的知识。读者必须了解英特尔x86-64 CPU系列的基本结构,否则将无法理解机器指令。
英特尔CPU系列通常被归类为冯·诺依曼体系结构的计算机。冯·诺依曼计算机系统包含三个主要的组成部分:中央处理器(CPU)、内存(memory)和输入/输出(I/O)设备。这三个组件通过系统总线(包括地址总线、数据总线和控制总线)互连。图1-1中的方框图显示了这三个组件之间的关系。
CPU通过在地址总线上放置一个数值,来选择一个内存位置或者I/O设备端口位置(每个位置都有一个唯一的数字地址),从而与内存或I/O设备通信。然后,CPU、内存和I/O设备这三个组件通过将数据放在数据总线上,实现数据传输。控制总线包含确定数据传输方向(从内存到I/O设备或从I/O设备到内存)的信号。
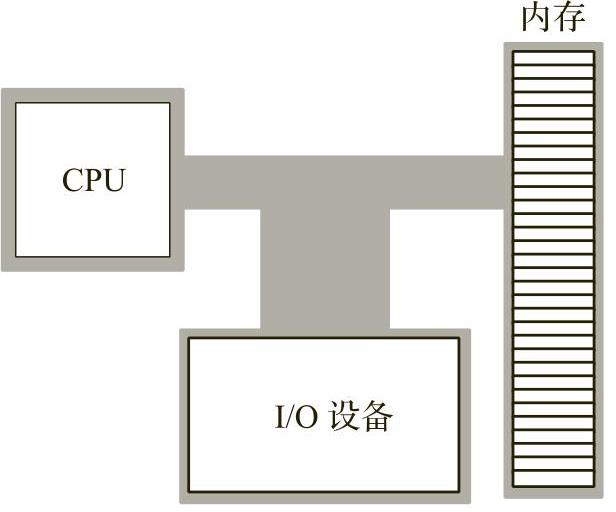
图1-1 冯·诺依曼计算机系统的方框图
在CPU中,寄存器(register)用于操作数据。x86-64 CPU的寄存器可分为四种类型:通用寄存器(general-purpose register)、专用应用程序访问寄存器(special-purpose application-accessible register)、段寄存器和专用内核模式寄存器(special-purpose kernel-mode register)。由于段寄存器在现代64位操作系统(例如Windows)中使用不多,因此本书中将不加讨论。专用内核模式寄存器用于编写操作系统、调试器和其他系统级的工具。这种软件构造远远超出了本书的讨论范围。
x86-64(英特尔系列)CPU提供多个通用寄存器供应用程序使用。通用寄存器包括如下几类。
●16个64位寄存器,对应的名称如下:RAX、RBX、RCX、RDX、RSI、RDI、RBP、RSP、R8、R9、R10、R11、R12、R13、R14和R15。
●16个32位寄存器,对应的名称如下:EAX、EBX、ECX、EDX、ESI、EDI、EBP、ESP、R8D、R9D、R10D、R11D、R12D、R13D、R14D和R15D。
●16个16位寄存器,对应的名称如下:AX、BX、CX、DX、SI、DI、BP、SP、R8W、R9W、R10W、R11W、R12W、R13W、R14W和R15W。
●20个8位寄存器,对应的名称如下:AL、AH、BL、BH、CL、CH、DL、DH、DIL、SIL、BPL、SPL、R8B、R9B、R10B、R11B、R12B、R13B、R14B和R15B。
遗憾的是,以上列举的68个寄存器都不是独立的寄存器。实际上,x86-64的64位寄存器覆盖在32位寄存器上,32位寄存器覆盖在16位寄存器上,16位寄存器覆盖在8位寄存器上。表1-1显示了这些寄存器之间的关系。
表 1-1 x86-64 上的通用寄存器
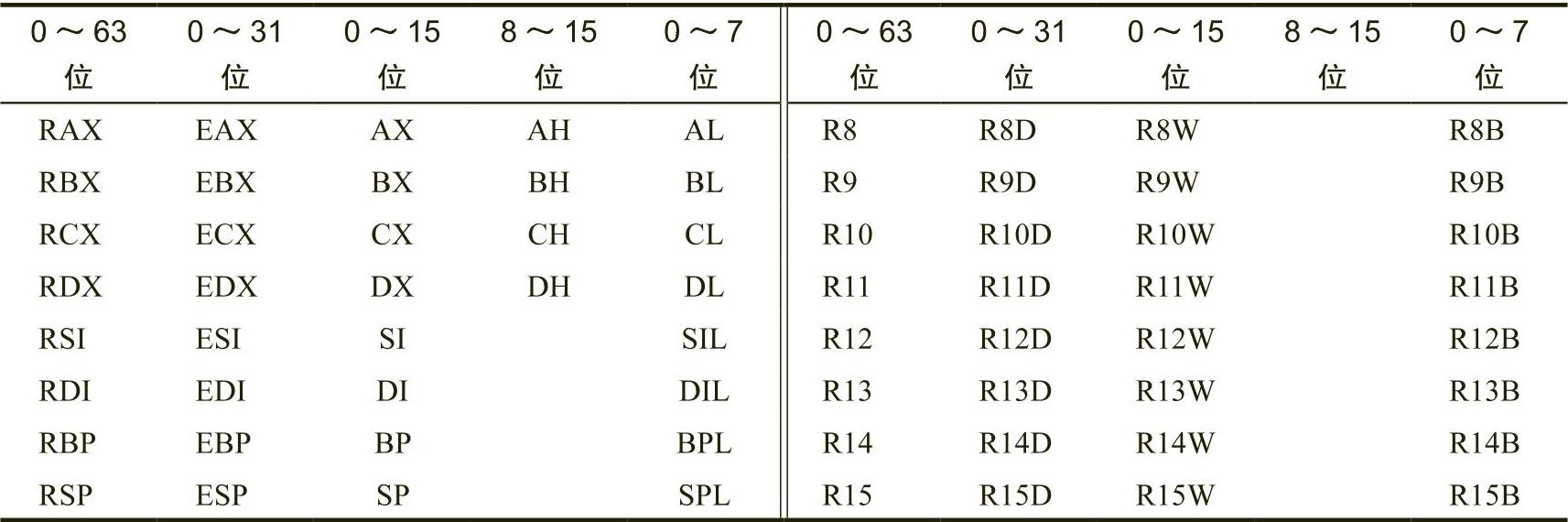
通用寄存器不是独立的寄存器,使得修改其中1个寄存器可能引发对其他寄存器的修改。例如,修改EAX寄存器的内容可能也会正好修改AL、AH、AX和RAX寄存器的内容。这一连锁反应现象需要引起足够的重视。在汇编语言初级程序员编写的程序中,一个常见的错误是寄存器值的损坏,这是程序员没有完全理解表1-1中所示关系的后果。
除通用寄存器外,x86-64还提供专用寄存器,包括在x87浮点单元(floating-point unit,FPU)中实现的8个浮点寄存器(floating-point register)。英特尔将这些寄存器命名为ST(0)到ST(7)。与通用寄存器不同,应用程序不能直接访问这些寄存器,它会将浮点寄存器文件视为一个可以包括8个项的栈,并只访问栈最上面的一个或两个项(有关更多的详细信息,可以参阅6.5节的相关内容)。
每个浮点寄存器的宽度为80位,包含一个扩展精度实数值(以下简称扩展精度)。尽管多年来英特尔在x86-64 CPU中增加了其他浮点寄存器,但FPU寄存器在代码中仍然很常用,因为这些寄存器支持这种80位的浮点格式。
20世纪90年代,英特尔推出了MMX寄存器集和指令,以支持单指令多数据(Single Instruction,Multiple Data,SIMD)操作。MMX寄存器集由8个64位的寄存器组成,覆盖FPU上的ST(0)至ST(7)寄存器。英特尔选择覆盖FPU寄存器,是因为这种方式使得MMX寄存器能够立即与多任务操作系统(例如Windows)兼容,而无须针对这些操作系统进行任何代码更改。遗憾的是,这种选择意味着应用程序不能同时使用FPU指令和MMX指令。
英特尔在x86-64的后续版本中通过添加XMM寄存器集解决了以上问题,因此用户很少看到使用MMX寄存器和指令集的现代应用程序。如果用户真想使用MMX寄存器和指令集,也不是不可以,但还是建议使用XMM寄存器(和指令集),同时将MMX寄存器保持为FPU模式。
为了打破MMX寄存器和FPU寄存器之间冲突带来的限制,AMD/英特尔增加了16个128位的XMM寄存器(XMM0到XMM15)和SSE/SSE2指令集。每个寄存器可以配置为4个32位的浮点寄存器,2个64位的双精度浮点寄存器,或者16个8位、8个16位、4个32位、2个64位或1个128位的整数寄存器。在x86-64 CPU系列的后续版本中,AMD/英特尔将寄存器的大小增加了一倍,每个寄存器的大小变为256位(并将这些寄存器重命名为YMM0到YMM15),以支持8个32位的浮点数值或者4个64位的双精度浮点数值(整数运算仍限制为128位)。
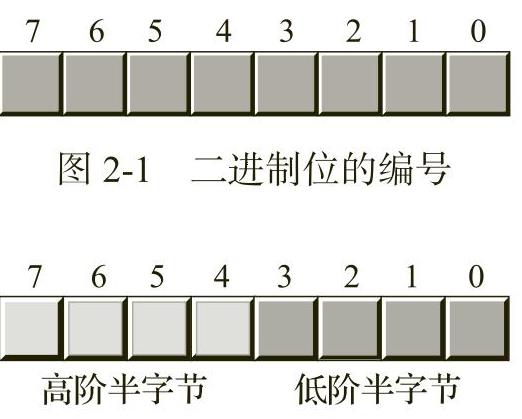
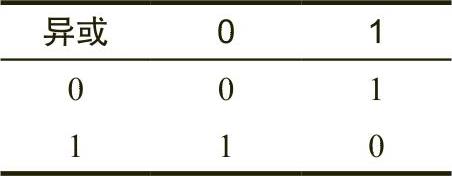
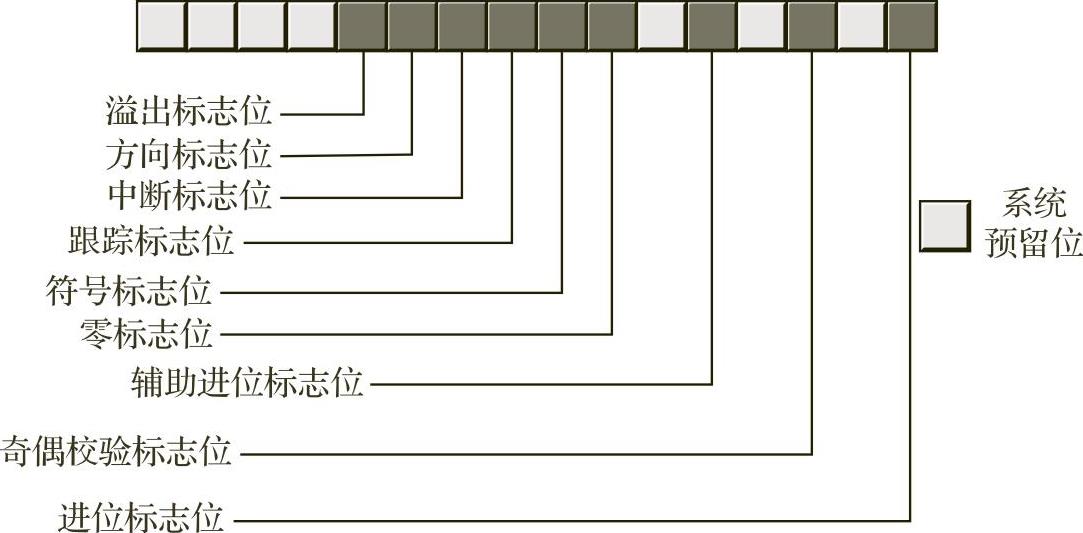
RFLAGS(或FLAGS)寄存器是一个64位寄存器,它封装了多个1位的布尔值(真/假)  。RFLAGS寄存器中的大多数位或者是为内核模式(操作系统)函数保留的位,或者是应用程序程序员不关心的位。编写汇编语言应用程序的程序员特别关注其中的8个位(或称为标志):溢出(overflow)、方向(direction)、中断(interrupt) 、符号(sign)、零(zero)、辅助进位(auxiliary carry)、奇偶校验(parity)以及进位(carry)标志。图1-2显示了RFLAGS寄存器低16位中各个标志位的布局。
。RFLAGS寄存器中的大多数位或者是为内核模式(操作系统)函数保留的位,或者是应用程序程序员不关心的位。编写汇编语言应用程序的程序员特别关注其中的8个位(或称为标志):溢出(overflow)、方向(direction)、中断(interrupt) 、符号(sign)、零(zero)、辅助进位(auxiliary carry)、奇偶校验(parity)以及进位(carry)标志。图1-2显示了RFLAGS寄存器低16位中各个标志位的布局。
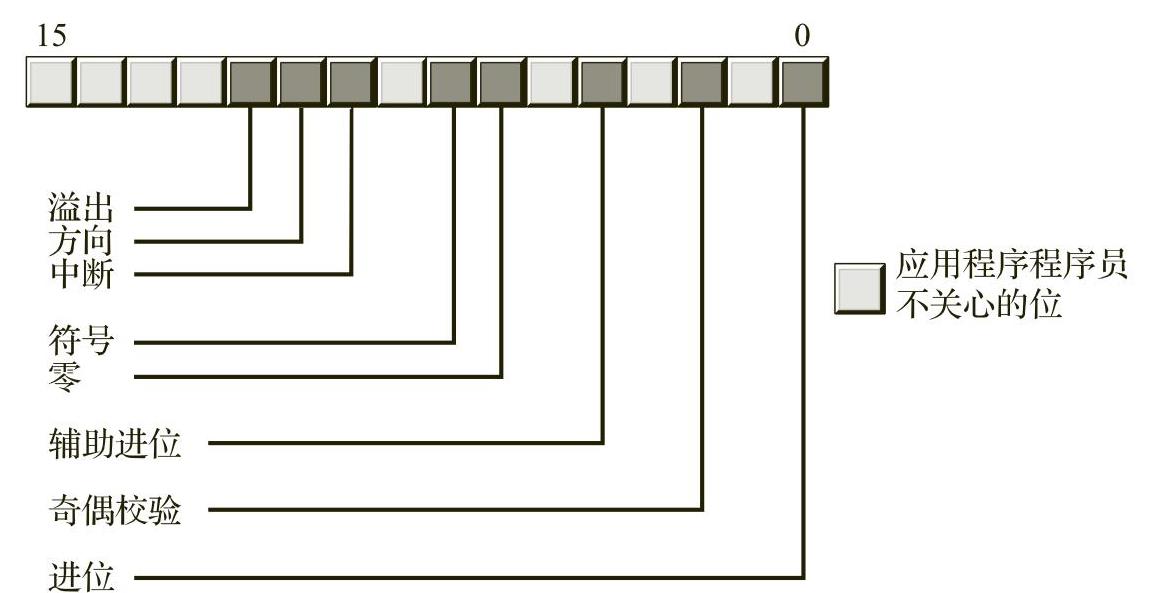
图1-2 RFLAGS寄存器的布局(位于RFLAGS寄存器的低16位)
在图1-2中,4个标志特别重要,分别是溢出、进位、符号和零标志,统称为条件码(condition code) 。这些标志的状态允许用户测试先前计算的结果。例如,比较两个值后,条件码标志将告知用户第一个值是否小于、等于或大于第二个值。
对于那些刚刚学习汇编语言的人而言,他们惊讶于一个重要事实,即x86-64 CPU上几乎所有的计算都涉及寄存器。例如,为了将两个变量相加并将总和存储到第三个变量中,就必须将其中一个变量加载到寄存器中,将第二个操作数与寄存器中的数值相加,然后将寄存器中的值存储到目标变量中。在几乎所有的计算中,都需要以寄存器作为中介。
用户还应该知道,尽管寄存器被称为通用寄存器,但用户不能将任何寄存器用于任何目的。所有x86-64寄存器都有自己的特殊用途,从而限制了寄存器在某些上下文中的使用。例如,RSP寄存器有一个非常特殊的用途,可以有效地防止用户将其用于任何其他用途(该寄存器是堆栈指针)。同样,RBP寄存器也有一个特殊用途,限制了其作为通用寄存器的作用。目前,用户应该避免使用RSP和RBP寄存器进行一般的计算任务;另外,请记住,其余寄存器在程序中不能完全互换。
1.8 内存子系统
内存子系统(memory subsystem)保存程序变量、常量、机器指令和其他信息等数据。内存由内存单元(或称为内存位置)组成,每个内存单元都保存着一小段信息。系统可以将来自这些小的内存单元的信息组合成更大的信息片段。
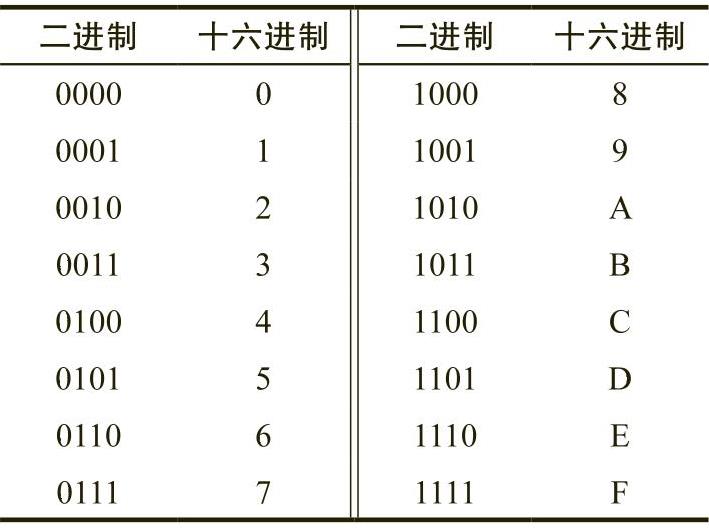
x86-64支持字节可寻址内存(byte-addressable memory),这意味着基本内存单元是一个字节,足以容纳单个字符或者(非常)小的整数值(我们将在第2章中详细讨论)。
可以把内存想象成一个线性字节数组,第一个字节的地址为0,最后一个字节的地址为2 32 -1。对于安装了4GB内存的x86处理器 [1]^ ,以下伪Pascal数组声明是对内存的最佳近似表示:
Memory:array[0..4294967295]of byte;
C/C++和Java用户可能更喜欢以下的语法:
byte Memory[4294967296];
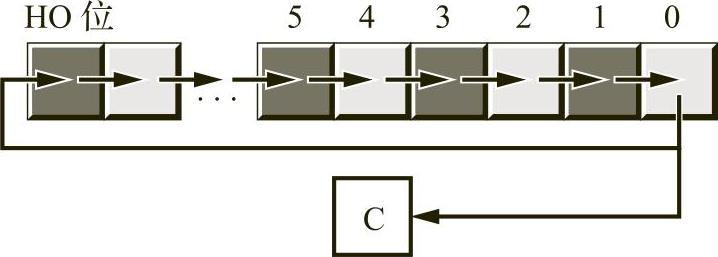
例如,为了执行等价于Pascal语句“Memory[125]:=0;”的操作,CPU将值0放在数据总线上,将地址125放在地址总线上,并断言写入线(该操作通常将该写入线设置为0),如图1-3所示。
为了执行等价于语句“CPU:=Memory[125];”的操作,CPU将地址125放置在地址总线上,并断言读取线(因为CPU正在从内存读取数据),然后从数据总线读取结果数据(请参见图1-4)。
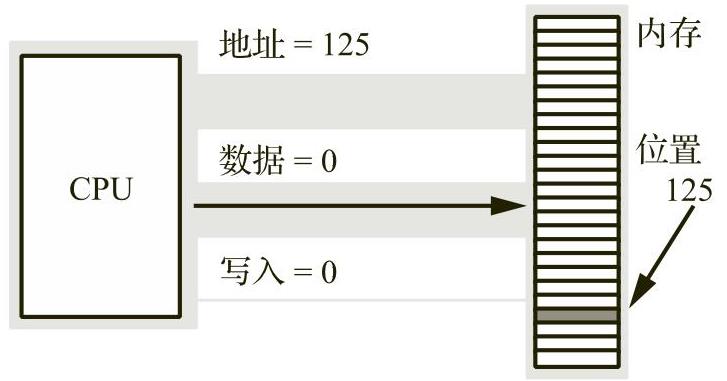
图1-3 内存写入操作
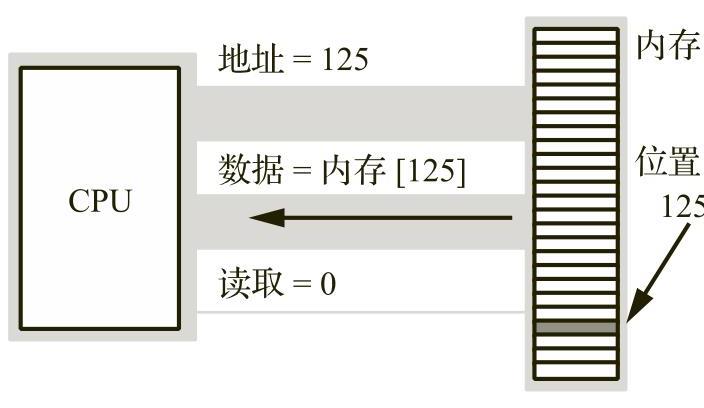
图1-4 内存读取操作
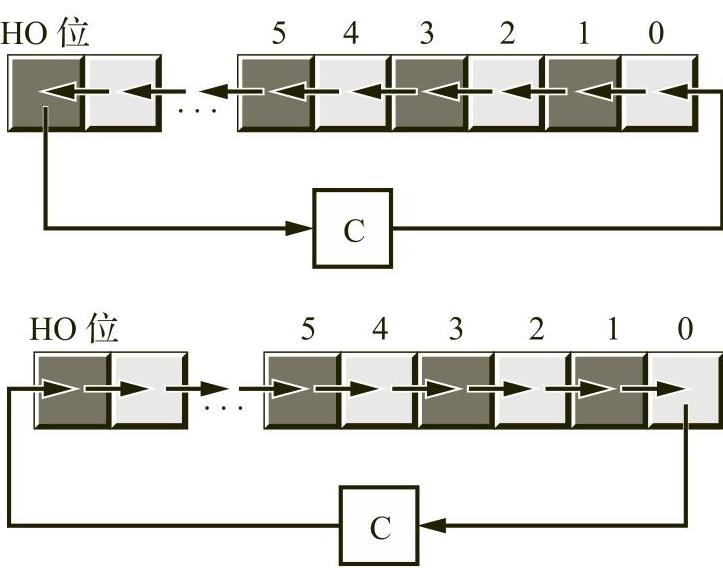
为了存储更大的值,x86使用一系列连续的内存位置。图1-5显示了x86如何在内存中存储字节、字(2个字节)和双字(4个字节)。对象的内存地址是其第一个字节的地址(即最低地址)。
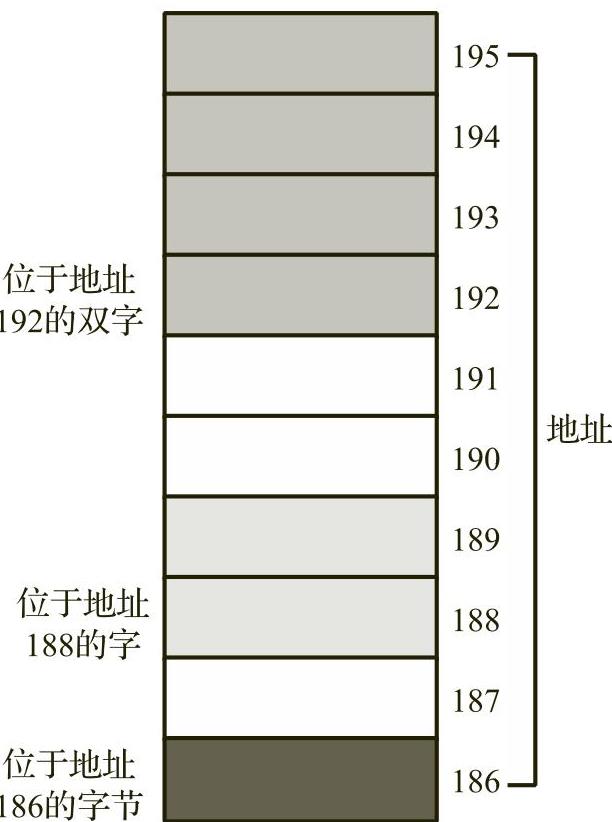
图1-5 内存中字节、字和双字的存储方式
1.9 在 MASM 中声明内存变量
在汇编语言中,虽然可以使用数字地址引用内存,但这样做非常麻烦,而且容易出错。与其在程序中声明如下语句:“获取内存地址192处的32位值,获取内存地址188处的16位值”,不如采用这个声明更加优雅:“获取变量elementCount的内容,获取变量portNumber的内容”。使用变量名而不是内存地址,可以使程序更易于编写、阅读和维护。
为了创建(可写入的)数据变量,必须将数据变量放在MASM源文件的数据段中,数据段使用“.data”伪指令定义。该伪指令指示MASM:以下所有语句(直到下一个“.code”伪指令或其他段定义伪指令出现)将定义数据声明,并被分组到内存的读取/写入段中。
在“.data”段中,MASM允许用户使用一组数据声明伪指令来声明变量对象。数据声明伪指令的基本形式如下:
label directive?
其中,label是一个合法的MASM标识符,directive是表1-2中显示的一个伪指令。
表 1-2 MASM 数据声明伪指令
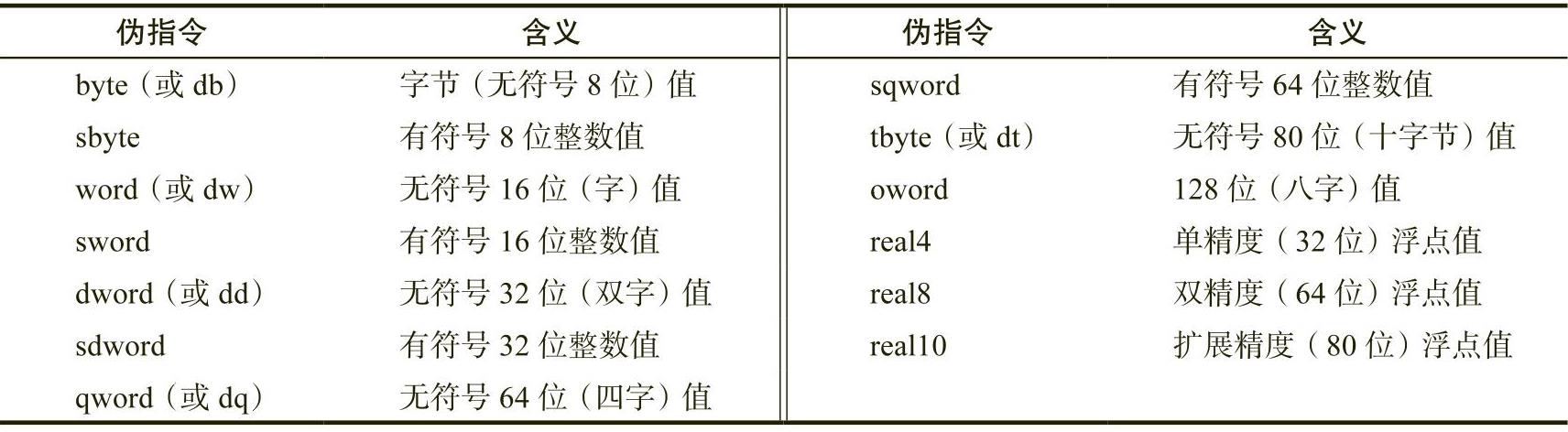
问号(?)操作数指示MASM:当程序加载到内存中时,对象是没有显式值的(默认初始化为0)。如果要使用显式值对变量进行初始化,则可以使用具体的初始值替换问号操作数。例如:
hasInitialValue sdword-1
表1-2中的一些数据声明伪指令(带有s前缀的伪指令)具有有符号版本。在大多数情况下,MASM会忽略此前缀。用户编写的机器指令会区分有符号和无符号操作,MASM本身则通常不关心变量是取有符号值还是无符号值。事实上,MASM允许以下两种情况:
.data
u8 byte-1;允许负的初始值
i8 sbyte 250;虽然+128是最大的有符号字节值,但此处仍然使用250
MASM关心的只是初始值是否放入一个字节中。即使“-1”不是一个无符号值,也可以放入内存的一个字节中。即使“250”超出了一个有符号8位整数的数值范围(请参阅2.7节的相关内容),MASM也会接受该初始值,因为它可以放入一个字节变量中(作为一个无符号数值)。
可以在单个数据声明伪指令中,为多个数据值保留存储空间。字符串多值数据类型对本章至关重要(后面的章节将讨论其他数据类型,如第4章中的数组)。用户可以使用如下byte伪指令在内存中创建以null结尾的字符串:
;0(null)结尾的C/C++字符串。
strVarName byte 'String of characters',0
请注意,字符串后面包含“,0”。在任何数据声明(不仅仅是字节声明)中,都可以在操作数字段中放置多个数据值,并用逗号分隔各数据值,MASM将为每个操作数定义一个指定大小和值的对象。对于字符串值(在本例中字符串值包括在单引号中),MASM为字符串中的每个字符定义一个字节(加上一个零字节,表示字符串末尾的“,0”操作数)。MASM允许用户使用单引号或双引号来定义字符串,并且必须使用与字符串开头相同的分隔符(单引号或双引号)终止字符串。
1.9.1 将内存地址与变量关联
使用MASM这样的汇编器/编译器的一个优势在于,用户不必关心数值形式的内存地址。用户只须在MASM中声明一个变量,MASM会将该变量与一组唯一的内存地址相关联。例如,假设用户定义了以下声明段:
.data
i8 sbyte ?
i16 sword ?
i32 sdword ?
i64 sqword ?
MASM将在内存中查找一个未使用的(8位)字节,并将其与变量i8相关联;查找两个未使用且连续的字节,并将这两个字节与变量i16相关联;查找四个未使用且连续的字节,并将这四个字节与变量i32相关联;查找八个未使用且连续的字节,并将这八个字节与变量i64相关联。用户只需要按名称引用这些变量,通常不必关心变量所关联的数值地址。不过,用户应该知道是MASM完成了这些关联操作。
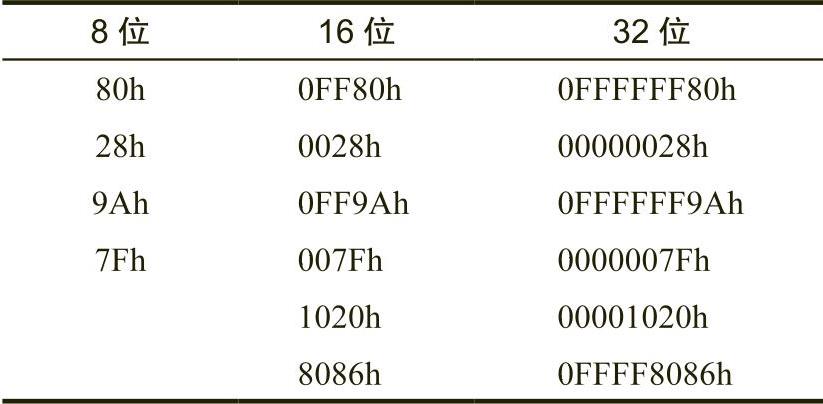
当MASM处理“.data”段中的声明时,将为每个变量分配连续的内存位置 。假设前面声明的变量i8位于内存地址101,则MASM将把表1-3中出现的地址分配给变量i8、i16、i32和i64。
当数据声明语句中有多个操作数值时,MASM会按照值在操作数字段中出现的顺序将值输出到连续的内存位置。与数据声明关联的标签(如果存在)将与第一个(最左侧)操作数值的地址相关联。具体请参见第4章。
表 1-3 变量地址分配

1.9.2 将数据类型与变量关联
在汇编过程中,MASM将数据类型与用户定义的每个标签(包括变量)相关联。这对于汇编语言来说属于相当高级的操作,因为大多数汇编器只是将一个值或地址与一个标识符相关联。
在大多数情况下,MASM使用变量的大小(字节)作为其数据类型(请参见表1-4)。
表 1-4 MASM 数据类型

后续章节将全面讨论proc、label、constant和text类型。
1.10 在 MASM 中声明(命名)常量
MASM允许用户使用“=”伪指令声明明示常量(manifest constant,也被称为明显常量)。明示常量是一个符号名称(标识符),MASM将该符号名称与一个值相关联。无论符号名称出现在程序中的何处,MASM都将直接使用与符号名称对应的值替换该符号名称。
明示常量的声明采用以下形式:
label=expression
其中,label是一个合法的MASM标识符,expression是一个常量算术表达式(通常是单个字面常量值)。以下示例定义符号名称dataSize等于256:
dataSize=256
大多数情况下,MASM的“equ”伪指令是“=”伪指令的同义词。就本章而言,以下语句大体上等同于上面的常量声明:
dataSize equ 256
常量声明(等同于MASM术语)可以位于MASM源文件的任何位置,但必须位于常量首次使用之前。常量声明可以在“.data”段中、“.code”段中,也可以在任何段之外。
1.11 基本的机器指令
根据用户定义机器指令的方式,x86-64 CPU系列提供了多达几百条到数千条的机器指令。但是大多数汇编语言程序使用大约30条到50条机器指令 ,而且只需要几条指令就可以编写若干有意义的程序。本节介绍少量机器指令,以便用户可以立即开始编写简单的MASM汇编语言程序。
1.11.1 mov 指令
毫无疑问,mov指令是最常用的汇编语言语句。在典型的程序中,25%到40%的指令都是mov指令。顾名思义,这条指令将数据从一个位置移动到另一个位置 。mov指令的通用MASM语法形式如下所示:
mov destination_operand,source_operand
source_operand(源操作数)可以是(通用)寄存器、内存变量或常量。destination_operand(目标操作数)可以是寄存器或者内存变量。x86-64指令集不允许两个操作数都是内存变量。在高级程序设计语言(例如Pascal或C/C++)中,mov指令大致相当于以下的赋值语句:
destination_operand=source_operand;
mov指令的两个操作数必须大小相同。也就是说,用户可以在两个字节(8位)对象、字(16位)对象、双字(32位)对象或者四字(64位)对象之间移动数据,但是不能混合操作数的大小。表1-5列出了mov指令的所有合法操作数组合。
建议用户仔细研究一下表1-5,因为大多数通用x86-64指令都使用此语法。
表 1-5 x86-64 mov 指令的合法操作数组合

(续)

①reg n 表示 n 位寄存器,mem n 表示 n 位内存位置。
②常量必须足够小,以便可以放入指定的目标操作数。
在表1-5中,需要注意一个重要事项:x86-64仅允许将32位的常量值移动到64位的内存单元(对32位的常量值进行符号扩展,达到64位。有关符号扩展的更多信息,请参见2.8节中的相关内容)。允许64位常量操作数的唯一一条x86-64指令是将64位常量移动到64位寄存器的指令。x86-64指令集中的这种不一致性会令人感到恼火,但是仍然推荐使用x86-64!
1.11.2 指令操作数的类型检查
MASM对指令操作数强制执行某些类型检查,特别是要求指令操作数的大小必须一致。例如,对于以下的代码,MASM将生成错误信息:
i8 byte ?
.
.
.
mov ax,i8
问题在于,用户试图将8位变量(i8)加载到16位寄存器(AX)中。由于两者的大小不兼容,因此MASM假定这是程序中的逻辑错误,并报告错误信息 。
在大多数情况下,MASM将忽略有符号变量和无符号变量之间的差异。对于以下两条mov指令,MASM不会报错:
i8 sbyte ?
u8 byte ?
.
.
.
mov al,i8
mov bl,u8
MASM关心的只是我们是否将字节变量移动到了字节大小的寄存器中。区分这些寄存器中有符号和无符号值的任务则交给应用程序。MASM甚至允许以下的操作:
r4v real4 ?
r8v real8 ?
.
.
.
mov eax,r4v
mov rbx,r8v
同样,MASM真正关心的只是内存操作数的大小,至于将浮点变量加载到通用寄存器(通常保存整数值)中的操作,MASM将不加干涉。
在表1-4中,包含proc、label和constant类型。如果用户试图在mov指令中使用proc(过程)或label(标签)保留字,则MASM将报告错误信息。过程或标签类型与机器指令的地址相关联,而不是与变量相关联,况且将过程加载到寄存器中是没有任何意义的。
但是,用户可以指定一个constant符号名称作为指令的源操作数,例如:
someConst=5
.
.
.
mov eax,someConst
由于常量没有大小,因此MASM对常量操作数进行的唯一类型检查是验证常量是否可以放入目标操作数中。例如,MASM将拒绝执行以下的代码:
wordConst=1000
.
.
.
mov al,wordConst
1.11.3 add 和 sub 指令
x86-64中的add和sub指令分别对两个操作数进行加法和减法运算。这两条指令的语法与mov指令几乎相同:
add destination_operand,source_operand
sub destination_operand,source_operand
但是,常量操作数的最大值限制为32位。如果目标操作数为64位,CPU仅允许32位的立即源操作数(则它将该操作数进行符号扩展至64位。有关符号扩展的详细信息,请参见2.8节中的相关内容)。
add指令执行以下的操作:
destination_operand=destination_operand+source_operand
sub指令执行以下的操作:
destination_operand=destination_operand-source_operand
有了这三条指令,再加上一些MASM的控制结构,用户就可以编写复杂的汇编程序了。
1.11.4 lea 指令
有时用户需要将变量的地址加载到寄存器中,而不是加载该变量的值。为此,可以使用lea(load effective address,加载有效地址)指令。lea指令采用以下的语法形式:
lea reg64,memory_var
这里,reg64是任何通用的64位寄存器,memory_var是变量名。请注意,该指令与memory_var的类型无关,不要求其类型为qword变量(与mov、add和sub指令一样)。每个变量都有一个与其相关联的内存地址,并且该地址始终为64位。以下示例将strVar字符串中第一个字符的地址加载到RCX寄存器中:
strVar byte"Some String",0
.
.
.
lea rcx,strVar
lea指令大致相当于C/C++的一元运算符“&”(address-of,取地址)。上述汇编程序示例在概念上等同于以下C/C++代码:
char strVar[]="Some String";
char * RCX;
.
.
.
RCX=&strVar[o];
1.11.5 call 和 ret 指令以及 MASM 过程
为了进行函数调用(以及编写自己的简单函数),用户需要使用call和ret指令。
ret指令在汇编语言程序中的作用与return语句在C/C++中的作用相同:该指令从汇编语言过程(汇编语言中称函数为过程)中返回控制权。本书暂且使用ret指令的变体,该变体没有操作数:
ret
ret指令允许使用单个操作数,但与C/C++语言不同,操作数不指定函数返回值。
用户可以使用call指令调用MASM过程。这个指令可以采取两种形式,最常见的语法形式如下:
call proc_name其中,proc_name是用户想要调用的过程的名称。
正如我们已经讨论的若干代码示例所示,MASM过程包含以下代码行:
proc_name proc然后是过程主体(通常以ret指令结束)。在过程结束时(通常紧随ret指令之后),使用以下语句来结束过程:
proc_name endp
endp伪指令上的标签必须与用户为proc语句提供的标签相同。
在程序清单1-4中的独立汇编语言程序中,主程序调用myProc过程,该过程将立即返回到主程序,然后主程序立即返回到Windows。
程序清单 1-4 汇编语言程序中的用户定义过程示例


用户可以使用以下命令编译以上的程序,并尝试运行该程序:
C:\> ml64 listing1-4.asm/link/subsystem:console/entry:main
Microsoft(R)Macro Assembler(x64)Version 14.15.26730.0
Copyright(C)Microsoft Corporation.All rights reserved.
Assembling:listing1-4.asm
Microsoft(R)Incremental Linker Version 14.15.26730.0
Copyright(C)Microsoft Corporation.All rights reserved.
/OUT:listing1-4.exe
listing1-4.obj
/subsystem:console
/entry:main
C:\> listing1-4
1.12 调用 C/C++ 过程
编写自定义的过程并对其加以调用,是一种非常有效的程序设计方式,但本章引入过程的原因并不是让用户编写自定义过程,而是训练用户具备调用C/C++过程(函数)的能力。编写自定义的过程,以将数据转换并输出到控制台是一项相当复杂的任务(目前为止可能远远超出用户的能力范围)。不过,用户可以调用C/C++语言中的printf()函数来生成程序输出,并在运行程序时验证程序是否确实在执行某些操作。
如果用户在汇编语言代码中调用printf(),而不提供printf()过程的定义,那么MASM会给出如下的错误信息:“使用了未定义的符号”。为了在源文件外部调用过程,需要使用MASM的externdef伪指令 。externdef伪指令的语法形式如下所示:
externdef symbol : type
此处,symbol是用户想要定义的外部符号,type是该符号的类型(定义外部过程时,类型是proc)。为了在汇编语言源文件中定义printf()符号,可以使用以下语句:
externdef printf:proc
当定义外部过程符号时,应将externdef伪指令放在“.code”段中。
externdef伪指令不允许向printf()过程指定需要传递的参数,call指令也不提供指定参数的机制。取而代之的是,用户可以使用x86-64的寄存器RCX、RDX、R8和R9,向printf()函数传递最多4个参数。printf()函数要求第一个参数是格式字符串的地址。因此,在调用printf()之前,应该将字符串的地址加载到RCX寄存器,注意,该字符串以零结尾。如果格式字符串包含任何格式说明符(例如,%d),则必须在寄存器RDX、R8和R9中传递适当的参数值。第5章将详细讨论过程参数,包括如何传递浮点值以及4个以上的参数。
1.13“Hello,world! ”程序
至此(本章前面包含大量篇幅),我们终于学习了足够知识,可以编写程序“Hello,world!”,如程序清单1-5所示。
程序清单 1-5“Hello,world! ”程序的汇编语言代码

在上述汇编语言代码中,包含两条“魔法”语句,本章暂不做进一步的解释。只需要接受这样一个事实:需要在函数开始时从RSP寄存器中减去56,然后在函数结束时将该值累加回RSP,才能正常地调用C/C++函数。第5章将更全面地解释这些语句的作用。
程序清单1-6中的C++函数调用汇编代码,并使得printf()函数可用。
程序清单 1-6 用于“ Hello,world! ”程序的 C++ 代码

在作者本人的计算机上编译和运行此代码所需的一系列步骤如下所示:
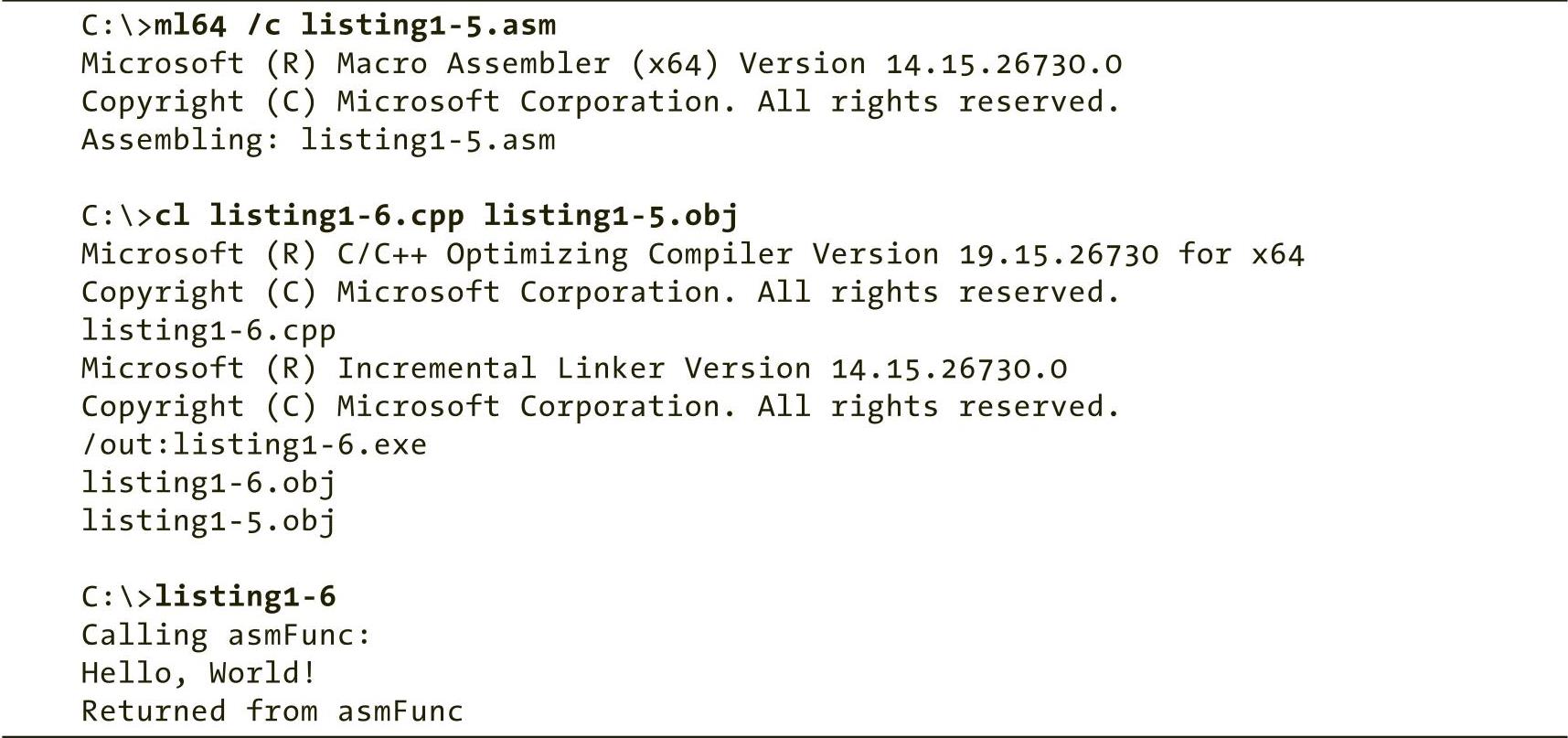
我们终于可以在控制台上输出“Hello,world!”字符串啦!
1.14 在汇编语言中返回函数结果
在上一节中,我们学习了向使用汇编语言编写的过程传递多达4个参数的方法。本节将描述其相反的过程:向调用过程的调用方代码返回值。
在纯汇编语言中(也就是一个汇编语言过程调用另一个汇编语言过程),严格而言,传递参数和返回函数结果是调用方(caller)和被调用方(callee)过程共享的约定。被调用方或者调用方可以选择函数结果出现的位置。
从被调用方的角度来看,返回值的过程确定调用方可以在哪里找到函数结果,并且调用该函数的调用方都必须尊重该选择。如果过程在XMM0寄存器(这是返回浮点结果的常用位置)中返回函数结果,那么调用该过程的调用方必须期望在XMM0中找到结果。而另一个不同的过程可以在RBX寄存器中返回其函数结果。
从调用方的角度来看,选择是相反的。现有代码期望函数在特定位置返回其结果,而被调用的函数必须遵守该期望。
遗憾的是,如果没有适当的协调机制,则一段代码可能会要求它调用的所有函数在一个位置返回函数结果,同时一组现有的库函数可能会坚持在另一个位置返回自己的函数结果。显然,这些函数与调用代码不兼容。虽然有一些方法可以处理这种情况[通常通过编写位于调用方和被调用方之间能够移动返回结果的外观(facade)代码],但最好的解决方案是确保各位编程人员在编写代码之前就在何处可以找到函数返回结果等事项达成协议。
此协议被称为应用程序二进制接口(application binary interface,ABI)。某种程度上,ABI是不同代码段之间的一种契约,描述调用约定(在哪里传递值,在哪里返回值,等等)、数据类型、内存使用和对齐,以及其他属性。CPU制造商、编译器编写者和操作系统供应商都提供自己的ABI。出于显而易见的原因,本书使用了Microsoft Windows ABI。
再次强调,必须充分理解在编写自己的汇编语言代码时,在过程之间传递数据的方式完全取决于用户自身。使用汇编语言的好处之一是,用户可以根据具体的过程来确定相应的接口。如果遵循ABI协议,那么用户只需要在调用自己无法控制的代码时(或者在外部代码调用自己的代码时)担心。本书涵盖了在Microsoft Windows下编写汇编语言(特别是与MSVC接口的汇编代码)的内容,因此在处理外部代码(Windows和C++代码)时,必须使用Windows/MSVC ABI。微软ABI指定,传递给printf()(或者任何C++函数)的前4个参数必须传递到RCX、RDX、R8和R9中。
Windows ABI还声明,函数(过程)会返回RAX寄存器中存储的整数和指针值(可以放入64位中)。因此,如果某些C++代码希望汇编程序返回一个整数结果,则汇编程序在返回之前需要将整数结果加载到RAX中。
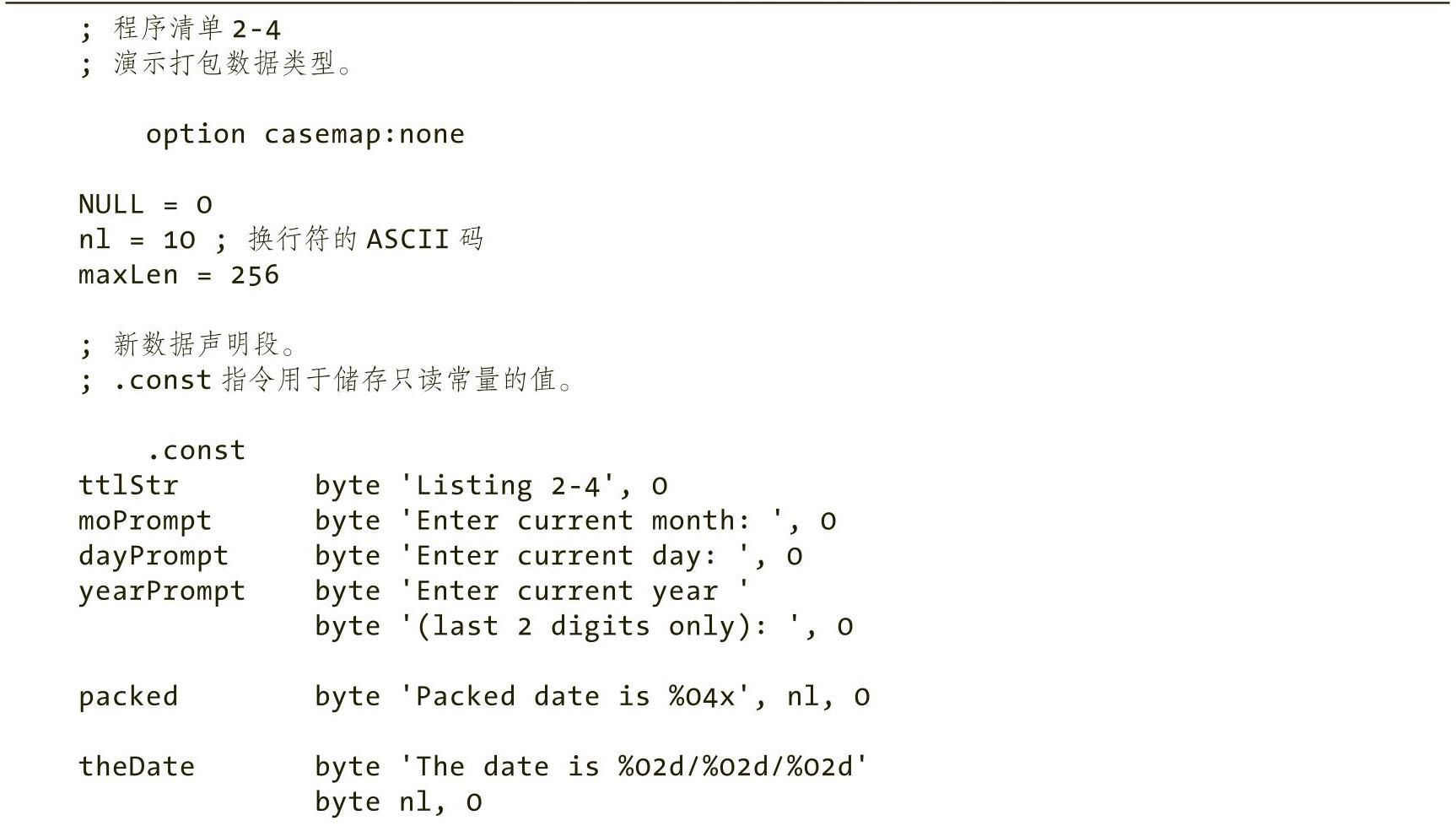
为了演示汇编程序如何返回函数结果,我们将使用程序清单1-7中的C++程序(c.cpp文件,这是本书之后演示大多数C++/汇编示例时使用的C++程序)。这个C++程序包括两个额外的函数声明:getTitle()(由汇编语言代码提供),该函数返回一个指向包含程序标题的字符串的指针(由C++代码打印这个标题);以及readLine()(由C++程序提供),汇编语言代码可以调用该函数从用户处读取一行文本(然后放入汇编语言代码的字符串缓冲区中)。
程序清单 1-7 调用汇编语言程序的通用 C++ 代码


try-catch语句块将捕获汇编代码生成的任何异常,当程序异常中止时,用户将得到某种提示。
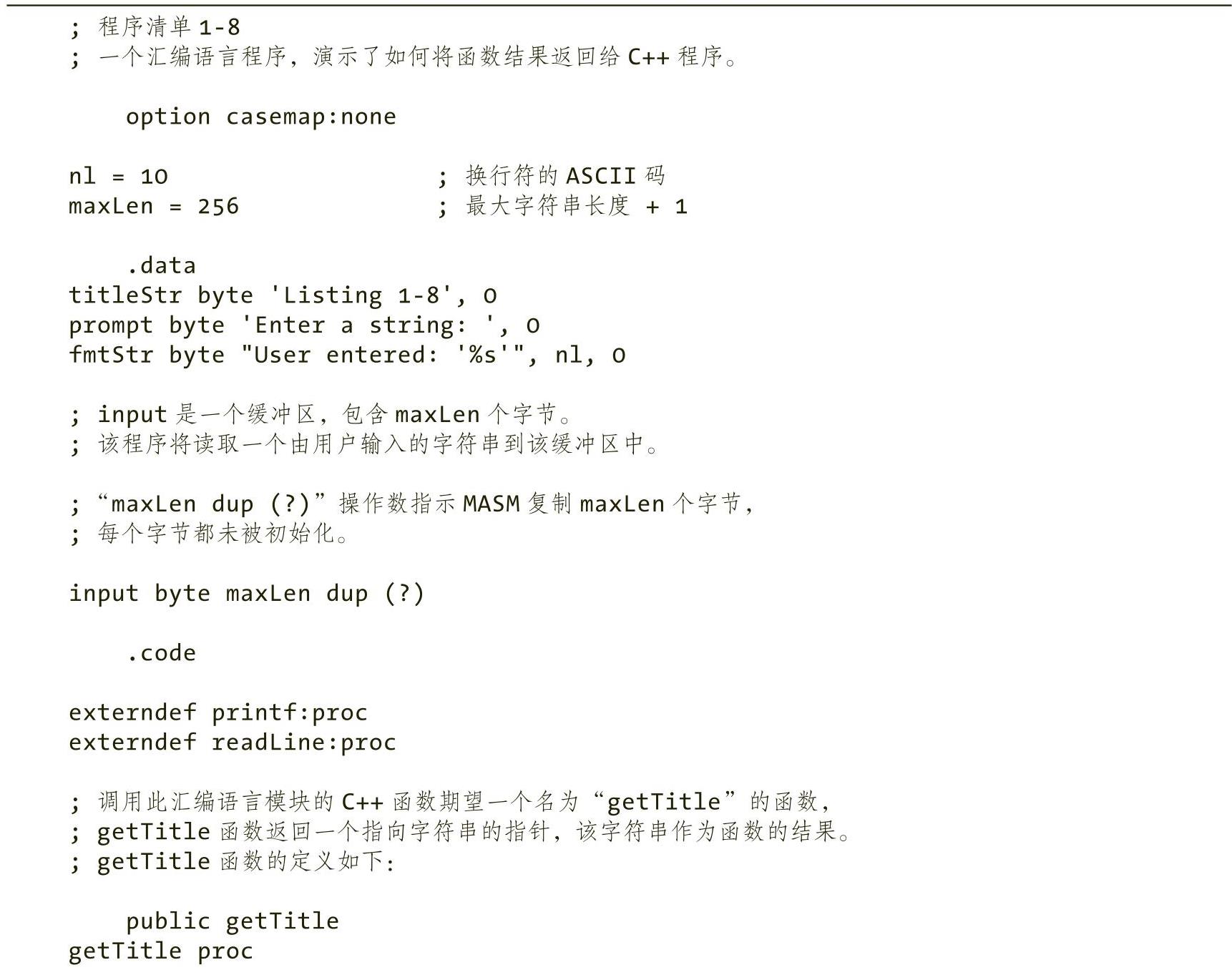
程序清单1-8提供的汇编代码演示了汇编语言中的一些新概念,第一个新概念是如何将函数的结果返回C++程序中。汇编语言函数getTitle()返回一个指向字符串的指针,调用方的C++代码将该字符串作为程序的标题进行打印。在“.data”段中,包含一个字符串变量titleStr,该变量初始化为该汇编代码的名称(即“Listing 1-8”)。getTitle()函数将该字符串的地址加载到RAX寄存器中,并将该字符串指针返回到C++代码中。C++代码在运行汇编代码之前和之后均会打印标题(具体请参见程序清单1-7)。
该程序还演示了如何从用户处读取一行文本。汇编代码调用C++代码中定义的readLine()函数,readLine()函数需要两个参数:字符缓冲区的地址(C字符串)和最大缓冲区长度。程序清单1-8中的代码通过RCX寄存器将字符缓冲区的地址传递给readLine()函数,并通过RDX寄存器将最大缓冲区长度传递给readLine()函数。最大缓冲区长度必须包含两个额外字符的空间,用于存放换行符和零终止字节。
最后,程序清单1-8演示了如何声明一个字符缓冲区(即一个字符数组)。在“.data”段中,包括以下声明:
input byte maxLen dup(?)
“maxLen dup(?)”操作数指示MASM复制(?)(即未初始化的字节)maxLen次。maxLen是一个常量,由源文件开头的等于伪指令“=”设置为256。(有关更多详细信息,请参阅4.9.1节中的相关内容。)
程序清单 1-8 返回函数结果的汇编语言程序

为了编译和运行程序清单1-7与程序清单1-8中的代码,可以使用如下的命令:
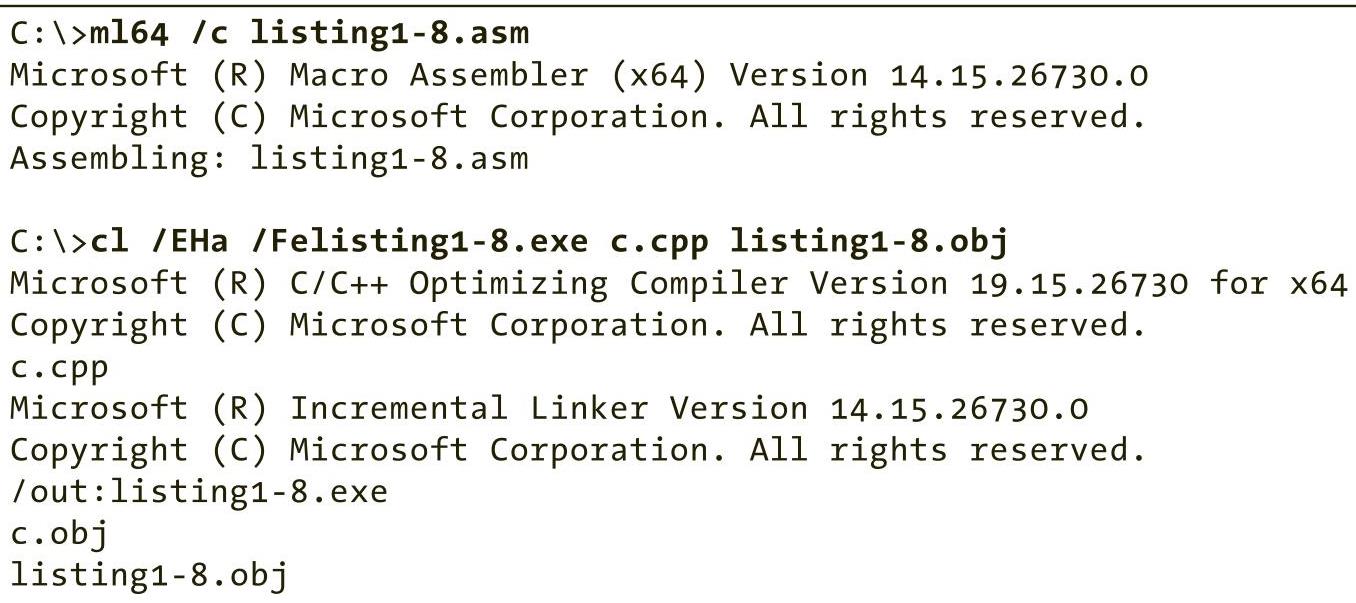
命令行中的选项“/Felisting1-8.exe”指示MSVC将可执行文件命名为listing1-8.exe。如果没有指定“/Fe”选项,那么MSVC将可执行文件命名为c.exe(因为程序清单1-7中的通用示例C++文件名保存为c.cpp,该文件在c.cpp之后)。
1.15 自动化构建过程
到目前为止,每当编译和运行程序时,都需要键入较长的命令行,用户可能会觉得有些麻烦。当用户开始向ml64和cl命令中添加更多命令行选项时,尤其感觉如此。请考虑以下的两个命令:
ml64/nologo/c/Zi/Cp listing1-8.asm
cl/nologo/O2/Zi/utf-8/EHa/Felisting1-8.exe c.cpp listing1-8.obj
listing1-8
“/Zi”选项指示MASM和MSVC将额外的调试信息编译到代码中。“/nologo”选项指示MASM和MSVC在编译期间跳过打印有关版权以及版本的信息。MASM的“/Cp”选项指示MASM在编译时不区分大小写(以便用户在编写汇编语言源文件中不需要使用“options casemap:none”伪指令)。“/O2”选项指示MSVC优化编译器生成的机器代码。“/utf-8”选项指示MSVC使用utf-8 Unicode进行编码(这是ASCII兼容的编码),而不是utf-16编码(或者其他字符编码)。“/EHa”选项指示MSVC处理处理器生成的异常(例如内存访问故障——汇编语言程序中一种常见的异常)。“/Fe”选项指定可执行的输出文件名。每当用户想要构建一个示例程序时,键入所有这些命令行选项将是一项艰巨的工作。
最简单的解决方案是创建一个批处理文件,使构建过程自动化。例如,用户可以在文本文件中键入前面的3个命令行,将该文本文件命名为l8.bat,然后只须在命令行中键入l8即可自动执行这3个命令。这省去了大量的键入工作,还不容易出错。
将这3个命令放入批处理文件的唯一缺点是,该批处理文件只适用于listing1-8.asm源文件,在编译其他程序时用户必须创建一个新的批处理文件。幸运的是,很容易创建一个用于处理任何单个汇编程序源代码文件的批处理文件,该批处理文件对汇编程序源文件进行编译,并链接到通用c.cpp程序。请考虑下面的build.bat批处理文件:
echo off
ml64/nologo/c/Zi/Cp%1.asm
cl/nologo/O2/Zi/utf-8/EHa/Fe%1.exe c.cpp%1.obj
这些命令中的“%1”项用于指示Windows命令行处理器,使用命令行参数(特别地,命令行参数数字1)代替%1。如果从命令行键入以下的内容:
build listing1-8
那么,Windows将执行以下3个命令:
echo off
ml64/nologo/c/Zi/Cp listing1-8.asm
cl/nologo/O2/Zi/utf-8/EHa/Felisting1-8.exe c.cpp listing1-8.obj
使用这个build.bat文件,只须在build命令行上指定汇编语言源文件名(不带.asm后缀),即可编译多个项目。
build.bat在编译并链接程序后,不会运行它。用户可以通过在批处理文件末尾附加一行包含%1的内容,将运行功能添加到批处理文件中。但是,当编译因为C++或汇编语言源文件中的错误而失败时,批处理文件也会尝试运行程序。因此,在使用批处理文件构建程序后,最好手动运行所生成的程序,如下所示:
C:\> build listing1-8
C:\> listing1-8
可以肯定的是,手动方式稍微多一些键入操作,但从长远来看更安全。
微软公司提供了另一个从命令行控制编译的有用工具:makefiles。这是一个比批处理文件更好的解决方案,因为makefiles允许用户根据前面步骤的成功情况,有条件地控制流程中的执行步骤(例如运行可执行文件)。但是,使用微软公司的make程序(nmake.exe)超出了本章的知识范围。make程序是一个值得学习的好工具(第15章将简单介绍该工具的基础知识)。然而,批处理文件对于本书大部分内容中出现的简单项目来说已经足够了,并且使用者只需要很少的额外知识或培训。如果用户有兴趣了解有关makefiles的更多信息,请参阅第15章或者1.17节。
1.16 微软 ABI 注释
微软ABI是一个程序中各个模块之间的契约,用于确保模块(特别是使用不同程序设计语言编写的模块)之间的兼容性 。在本书中,C++程序将调用汇编语言代码,汇编模块将调用C++代码,因此汇编语言代码必须遵守微软ABI的契约。
即使编写独立的汇编语言代码,也仍然会调用C++代码,因为将(毫无疑问地)调用Windows应用程序编程接口(application programming interface,API)。Windows API函数都是使用C++编写的,所以对Windows的调用必须遵循Windows ABI的契约。
由于遵循微软ABI的契约非常重要,因此本书每一章(如果适用的话)的最后都包括一小节,重点讨论本章介绍的或者大量使用的微软ABI组件。本节介绍微软ABI中的几个概念:变量大小、寄存器的用途和栈对齐。
1.16.1 变量大小
尽管在汇编语言中处理不同的数据类型完全取决于汇编语言程序员(以及对使用在该数据上的机器指令的选择),但在C++和汇编语言程序之间保持数据大小(以字节为单位)的一致性是至关重要的。表1-6列出了几种常见的C++数据类型和对应的汇编语言类型(类型中蕴含数据大小信息)。
表 1-6 C++ 和汇编语言类型
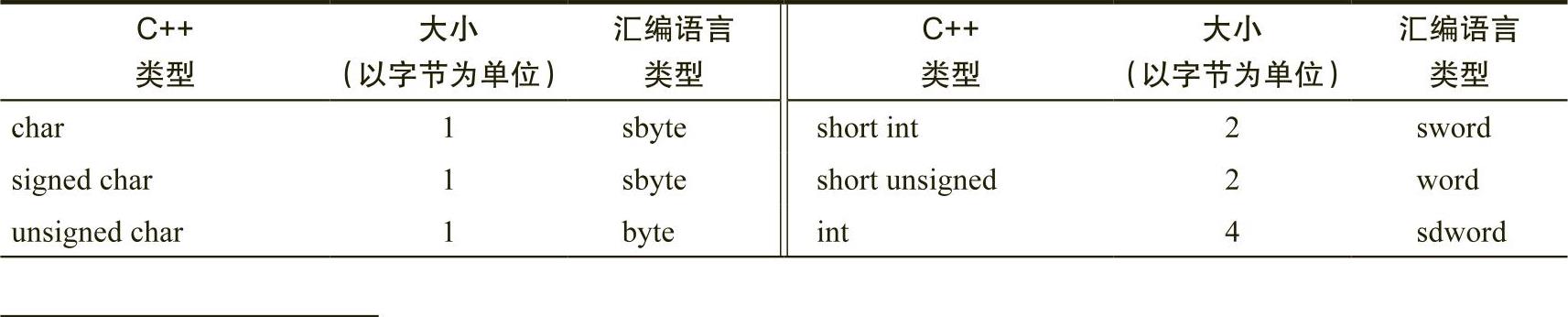
(续)
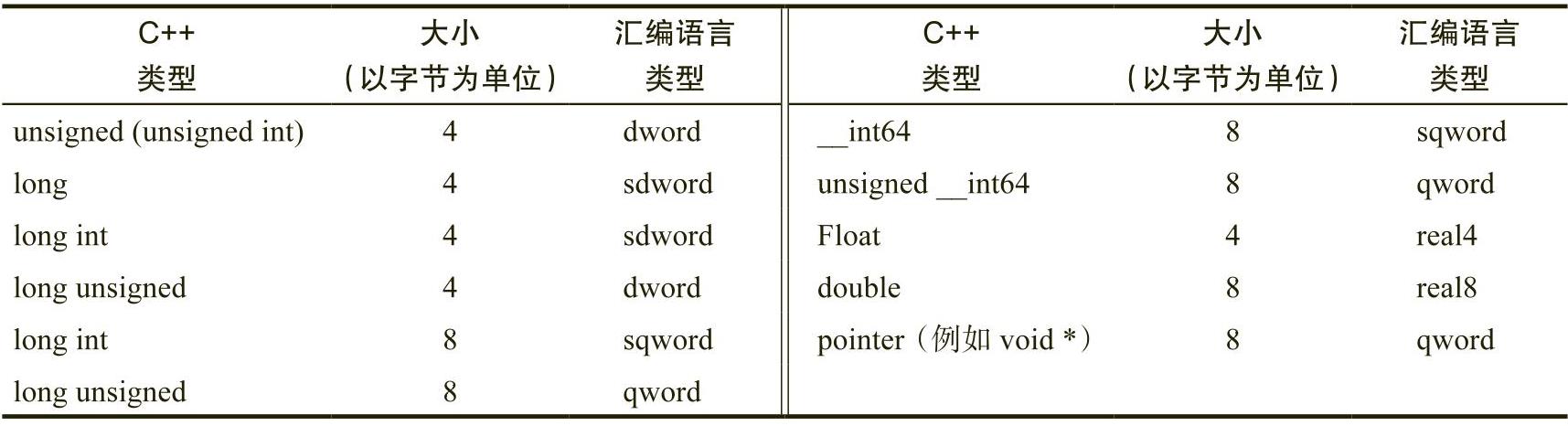
尽管MASM提供有符号类型声明(sbyte、sword、sdword和sqword),但汇编语言指令不区分无符号类型变体和有符号类型变体。可以使用无符号指令序列处理有符号整数(sdword),也可以使用有符号指令序列处理无符号整数(dword)。在汇编语言源文件中,这些不同的伪指令主要发挥文档辅助功能,用以帮助描述程序员的意图 。
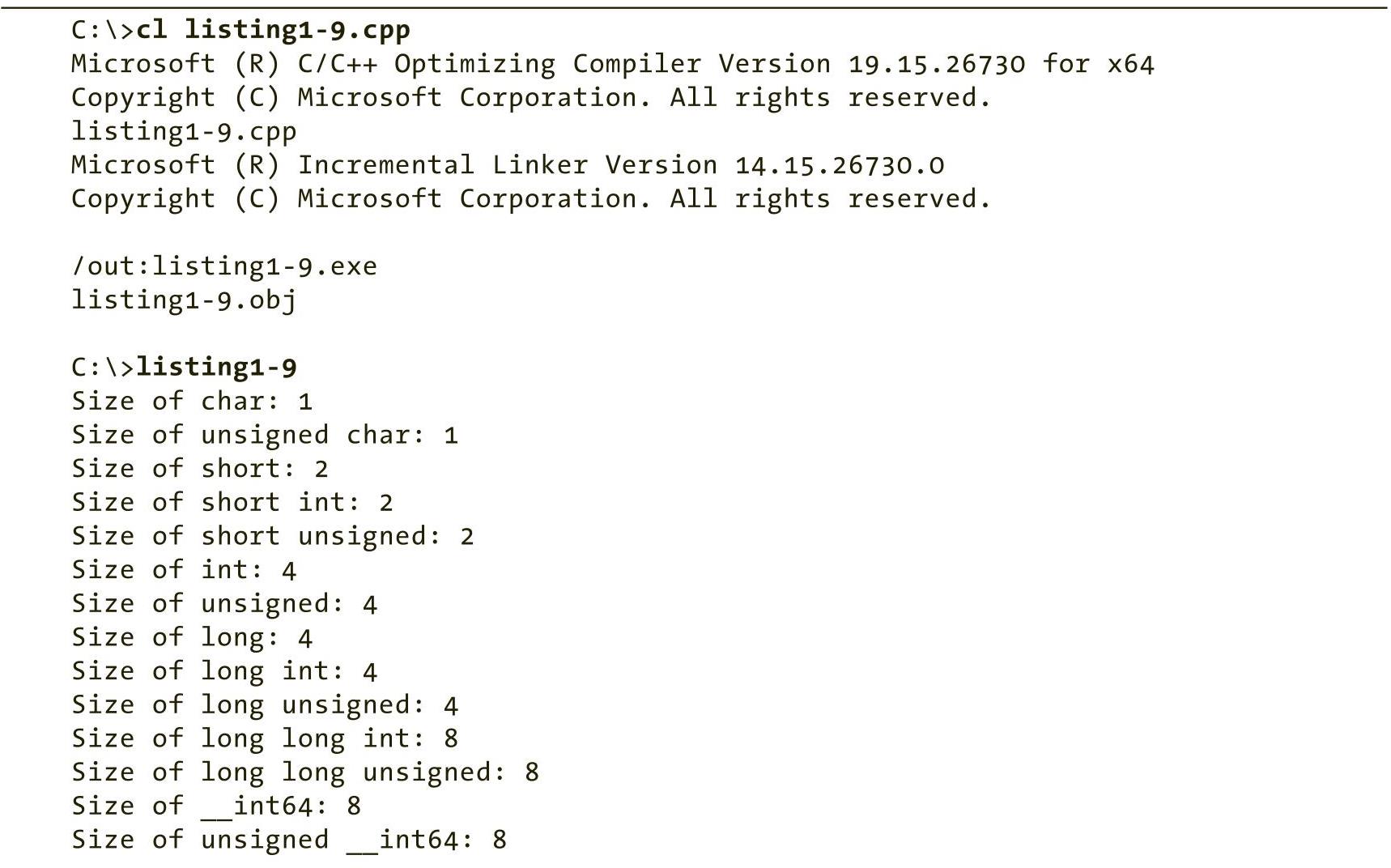
程序清单1-9是一个简单的程序,用于验证这些C++数据类型的大小。
注意: %2zd格式字符串显示size_t类型值(sizeof运算符返回size_t类型的值)。这样可以避免MSVC编译器产生警告信息(如果仅使用%2d,则会生成警告信息)。大多数编译器可以使用%2d。
程序清单 1-9 输出常见 C++ 数据类型的大小
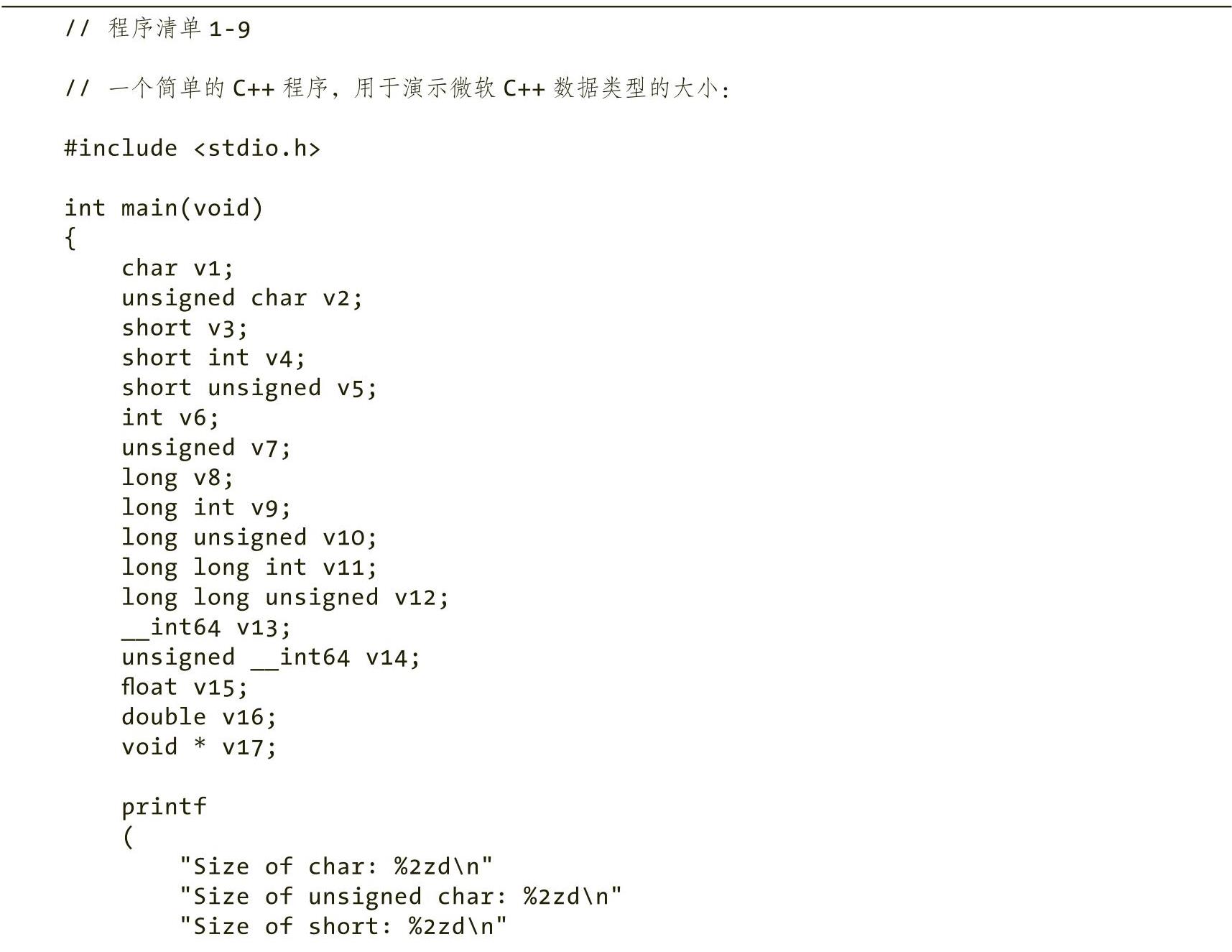

程序清单1-9的build命令和输出结果如下所示:

1.16.2 寄存器的用途
汇编语言过程(包括汇编语言主函数)中寄存器的用途(register usage)也受某些微软ABI规则的约束。在一个过程中,微软ABI对寄存器的用途有如下说明 。
●调用函数的代码可以通过寄存器RCX、RDX、R8和R9,将前四个(整数)参数分别传递给函数(过程)。程序可以通过寄存器XMM0、XMM1、XMM2和XMM3传递前四个浮点参数。
●寄存器RAX、RCX、RDX、R8、R9、R10和R11是易失性(volatile)寄存器,这意味着函数(过程)不需要在函数(过程)调用中保存寄存器的值。
●寄存器XMM0/YMM0到XMM5/YMM5也是易失性寄存器。函数(过程)不需要在调用过程中保存这些寄存器的值。
●寄存器RBX、RBP、RDI、RSI、RSP、R12、R13、R14和R15是非易失性(nonvolatile)寄存器。过程(函数)必须在调用过程中保存这些寄存器的值。如果一个过程修改了其中一个寄存器的值,则该过程必须在第一次修改之前保存寄存器的值,并在从函数(过程)返回之前从保存的位置恢复寄存器的值。
●寄存器XMM6到XMM15是非易失性寄存器。函数必须在调用其他函数(过程)期间保存这些寄存器的值(即当过程返回时,这些寄存器必须包含在进入该过程时所具有的相同值)。
●使用x86-64浮点协处理器指令的程序,必须在过程调用中保存浮点控制字的值。此类程序还应清除浮点栈的内容。
●任何使用x86-64方向标志位的过程(函数),必须在从过程(函数)中返回时清除该标志位。
微软C++期望函数返回值出现在以下两个位置。整数(和其他非标量)结果返回到RAX寄存器(最多64位)。如果返回值类型小于64位,则RAX寄存器的高位未定义。例如,如果函数返回短整型(16位)结果,则RAX寄存器中的第16位至第63位可能包含垃圾数据。微软的ABI规定,浮点(和向量)函数返回结果必须返回到XMM0寄存器。
1.16.3 栈对齐
在本章的源代码程序清单中,包含一些“魔法”指令,这些“魔法”指令基本上是从RSP寄存器中加或者减一个值。这些指令与栈对齐有关(这是微软ABI契约的要求)。本章(以及随后的几章)在代码中提供了这些指令,但没有做进一步解释。有关这些指令用途的更多详细信息,请参见第5章。
1.17 拓展阅读资料
本章涵盖了很多相关知识。虽然还有很多关于汇编语言程序设计的知识需要读者学习,但本章结合HLL(特别是C/C++),为读者提供了足够的信息,让读者可以开始编写真正的汇编语言程序。
本章涵盖了许多主题,其中三个主要的主题是x86-64 CPU体系结构、简单MASM程序的语法,以及与C标准库的接口。
以下资源提供了有关makefiles的更多信息:
●Wikipedia:https://en.wikipedia.org/wiki/Make_(software)。
● Managing Projects with GNU Make (Robert Mecklenburg,O'Reilly Media,2004)。
● The GNU Make Book (John Graham-Cumming,No Starch Press,2015)。
● Managing Projects with make (Andrew Oram and Steve Talbott,O'Reilly&Associates,1993)。
有关MVSC的更多信息:
●微软Visual Studio网站:https://visualstudio.microsoft.com/以及https://visualstudio.microsoft.com/vs/。
●微软自由开发者提供的网站:https://visualstudio.microsoft.com/free-developer-offers/。
有关MASM的更多信息:
●微软官网的C++、C以及汇编器文档:https://docs.microsoft.com/en-us/cpp/assembler/masm/masm-for-x64-ml64-exe?view=msvc-160/。
● The Waite Group's Microsoft Macro Assembler Bible (涵盖MASM 6。虽然MASM 6仅针对32位汇编语言程序设计,但是该书仍然包含大量有关MASM的参考信息):https://www.amazon.com/Waite-Groups-Microsoft-Macro-Assembler/dp/0672301555/。
有关ABI的更多信息:
●最完善的文档请参考Agner Fog的个人主页:https://www.agner.org/optimize/。
●以下微软网址也包含微软ABI调用约定的详细信息:https://docs.microsoft.com/en-us/cpp/build/x64-callingconvention?view=msvc-160。也可以在互联网上搜索Microsoft calling conventions关键词以获得更多信息。
1.18 自测题
1.Windows命令行解释器程序的名称是什么?
2.MASM可执行程序文件的名称是什么?
3.三条主要系统总线的名称是什么?
4.哪些寄存器覆盖了RAX寄存器?
5.哪些寄存器覆盖了RBX寄存器?
6.哪些寄存器覆盖了RSI寄存器?
7.哪些寄存器覆盖了R8寄存器?
8.哪个寄存器保存条件码标志位?
9.以下数据类型各占用多少个字节?
a.word
b.dword
c.oword
d.带一个“4 dup(?)”操作数的qword
e.real8
10.如果一个8位(字节)内存变量是mov指令的目标操作数,那么哪些源操作数是合法的?
11.如果mov指令的目标操作数是EAX寄存器,那么可以加载到该寄存器中的最大常量(以位为单位)是多少?
12.对于add指令,请填写下表中指定的所有目标操作数对应的最大常量大小(以位为单位)。

13.lea指令的目标(寄存器)操作数大小是多少?
14.lea指令的源(内存)操作数大小是多少?
15.用于调用过程或函数的汇编语言指令名称是什么?
16.用于从过程或函数返回的汇编语言指令名称是什么?
17.ABI表示什么含义?
18.在Windows ABI中,在何处返回以下的函数操作结果?
a.8位字节值
b.16位字值
c.32位整数值
d.64位整数值
e.浮点值
f.64位指针值
19.在何处将第一个参数传递给微软ABI兼容函数?
20.在何处将第二个参数传递给微软ABI兼容函数?
21.在何处将第三个参数传递给微软ABI兼容函数?
22.在何处将第四个参数传递给微软ABI兼容函数?
23.汇编语言中的哪种数据类型对应于C/C++程序设计语言中的long int?
24.汇编语言中的哪种数据类型对应于C/C++程序设计语言中的long long unsigned?
[1] 以下讨论将使用较旧的32位x86-64处理器的4GB地址空间。运行现代64位操作系统的典型x86-64处理器最多可访问2 48 个内存位置,或使用的地址空间略高于256TB。